Filtering corpora using Quality#
In many cases if you want to analyse tweets, train a model on text scraped from the web or similar, it is important to filter out low-quality texts.
TextDescriptives implements a series of heuristic filters for removing low-quality text. This tutorial will take you through how to use these to filter your text corpora.
Setup#
For this we will use datasets available on Huggingface Datasets. Thus we will need the datasets package. Which you can install by running
!pip install datasets
Or by installing textdescriptives with the [tutorials] option as below
try:
import textdescriptives as td
except:
!pip install "textdescriptives[tutorials]"
import textdescriptives as td
Filtering Web content#
The Data#
For our first example we will filter web content. For this we will use the mC4 dataset. It would take ages to download the whole data so instead we will stream down 1000 samples from the dataset.
from datasets import load_dataset
# stream in the dataset
dataset = load_dataset(
"mc4", "en", streaming=True, split="train", trust_remote_code=True
)
# download the first 1 000
dataset = dataset.take(1000)
# extract the text
texts = [sample["text"] for sample in dataset]
/Users/au561649/.cache/huggingface/modules/datasets_modules/datasets/mc4/78f7a2b7e2524fa44ee464ef429d011c365f5fe129283869e7fd76856aacb83a/mc4.py:284: FutureWarning: Dataset 'mc4' is deprecated and will be deleted. Use 'allenai/c4' instead.
warnings.warn(
# let us look at the first part (400 characters) of the first text
print(texts[0][:400])
Posts 4,362 More Info
Okay so to those of you that were very helpful this is not to you but for those of you that laugh when I ask about ohms or powering LSi15's this is to you. If you know a book, website, or someone to talk to to get more info that I seek so I know what some of you are talking about please share it with me. I ask questions to gain more info on audio thats all. Not to get laughed
Filtering#
To filter texts using textdescriptives we need to first set up the pipeline:
import spacy
# create the spacy nlp pipeline
nlp = spacy.blank("en")
# add a component for sentence segmentation
nlp.add_pipe("sentencizer")
# add a component for quality filtering
quality_pipe = nlp.add_pipe("textdescriptives/quality")
# apply the pipeline to the texts
docs = nlp.pipe(texts)
You will note here that docs is a generator. This can be quite useful (especially when streaming texts in one at a time), but for this example we can simply convert it to a list:
print(f"docs is type {type(docs)}")
docs = list(docs)
print(f"docs is type {type(docs)}")
docs is type <class 'generator'>
docs is type <class 'list'>
Now it is easy to examine the documents using the doc._.quality or doc._.passed_quality_check extensions:
# examine the first document
doc = docs[0]
print(doc[:100])
Posts 4,362 More Info
Okay so to those of you that were very helpful this is not to you but for those of you that laugh when I ask about ohms or powering LSi15's this is to you. If you know a book, website, or someone to talk to to get more info that I seek so I know what some of you are talking about please share it with me. I ask questions to gain more info on audio thats all. Not to get laughed at when asking it.
doc._.passed_quality_check
False
It seems like this document did no pass the quality check. Let us examine why that is:
doc._.quality
QualityOutput(
passed=False,
n_stop_words=ThresholdsOutput(value=435.0, passed=True, threshold=(2.0, None)),
alpha_ratio=ThresholdsOutput(value=0.79, passed=True, threshold=(0.7, None)),
mean_word_length=ThresholdsOutput(value=3.52, passed=True, threshold=(3.0, 10.0)),
doc_length=ThresholdsOutput(value=894.0, passed=True, threshold=(10.0, 100000.0)),
symbol_to_word_ratio={'#': ThresholdsOutput(value=0.0, passed=True, threshold=(None, 0.1))},
proportion_ellipsis=ThresholdsOutput(value=0.0, passed=True, threshold=(None, 0.3)),
proportion_bullet_points=ThresholdsOutput(value=0.0, passed=True, threshold=(None, 0.8)),
contains={'lorem ipsum': ThresholdsOutput(value=0.0, passed=True, threshold=False)},
duplicate_line_chr_fraction=ThresholdsOutput(value=0.0, passed=True, threshold=(None, 0.2)),
duplicate_paragraph_chr_fraction=ThresholdsOutput(value=0.0, passed=True, threshold=(None, 0.2)),
duplicate_ngram_chr_fraction={'5': ThresholdsOutput(value=0.42, passed=False, threshold=(None, 0.15)), '6': ThresholdsOutput(value=0.42, passed=False, threshold=(None, 0.14)), '7': ThresholdsOutput(value=0.38, passed=False, threshold=(None, 0.13)), '8': ThresholdsOutput(value=0.36, passed=False, threshold=(None, 0.12)), '9': ThresholdsOutput(value=0.36, passed=False, threshold=(None, 0.11)), '10': ThresholdsOutput(value=0.36, passed=False, threshold=(None, 0.1))},
top_ngram_chr_fraction={'2': ThresholdsOutput(value=0.01, passed=True, threshold=(None, 0.2)), '3': ThresholdsOutput(value=0.01, passed=True, threshold=(None, 0.18)), '4': ThresholdsOutput(value=0.01, passed=True, threshold=(None, 0.16))},
oov_ratio=ThresholdsOutput(value=None, passed=None, threshold=(None, None)))
Naturally, you might not know what all of these mean, but you can easily check it on the documentation site. Examining these we see that this text has a high proportion of characters which appear in duplicate n-grams duplicate_10-gram_chr_fraction. When this fraction is really high it means that the text contains a high proportion of repititions. This is often a sign of low quality text.
If we examine the quality thresholds of the pipeline we can see that the max allowed value for duplicate_10-gram_chr_fraction is 0.1:
print(quality_pipe.quality_thresholds)
print("---")
print("The thresholds for Duplicate n-grams:")
print(quality_pipe.quality_thresholds.duplicate_ngram_chr_fraction)
n_stop_words=(2, None) alpha_ratio=(0.7, None) mean_word_length=(3, 10) doc_length=(10, 100000) symbol_to_word_ratio={'#': (None, 0.1)} proportion_ellipsis=(None, 0.3) proportion_bullet_points=(None, 0.8) contains={'lorem ipsum': False} duplicate_line_chr_fraction=(None, 0.2) duplicate_paragraph_chr_fraction=(None, 0.2) duplicate_ngram_chr_fraction={'5': (None, 0.15), '6': (None, 0.14), '7': (None, 0.13), '8': (None, 0.12), '9': (None, 0.11), '10': (None, 0.1)} top_ngram_chr_fraction={'2': (None, 0.2), '3': (None, 0.18), '4': (None, 0.16)} oov_ratio=(None, 0.2)
---
The thresholds for Duplicate n-grams:
{'5': (None, 0.15), '6': (None, 0.14), '7': (None, 0.13), '8': (None, 0.12), '9': (None, 0.11), '10': (None, 0.1)}
Extracting high quality texts#
We are typically interested in text which are not of low quality. We can extract these by filtering out the texts which did not pass the quality check.
filtered_texts = [doc for doc in docs if doc._.passed_quality_check]
print(
f"A total of {len(docs)} texts were processed and {len(filtered_texts)} passed the quality check."
)
A total of 1000 texts were processed and 572 passed the quality check.
Changing the filters#
In some cases you might want to apply other filters. For instance the current filter sets a symbol_to_word_ratio threshold of 0.1 for hashtags #. This means that if a text contains a lot of hashtags it will be filtered out. However if you are working on e.g. tweets this is an unreasonable filter and you might want to adjust that. You can do this by overwriting the quality_thresholds:
new_thresholds = td.QualityThresholds(
n_stop_words=(2, None), # at least 2 stop words, no upper bound
alpha_ratio=(0.7, None),
mean_word_length=(3, 10), # mean word length between 3 and 10 characters
doc_length=(10, 100_000),
symbol_to_word_ratio={}, # don't filter based on symbol to word ratio.
proportion_ellipsis=(None, 0.3),
proportion_bullet_points=(None, 0.8),
contains={
"lorem ipsum": False
}, # remove texts which contain the string "lorem ipsum"
duplicate_line_chr_fraction=(None, 0.2),
duplicate_paragraph_chr_fraction=(None, 0.2),
duplicate_ngram_chr_fraction={}, # don't filter based on duplicate n-grams
top_ngram_chr_fraction={"2": (None, 0.2), "3": (None, 0.18), "4": (None, 0.16)},
)
# overwrite the existing thresholds
quality_pipe.set_quality_thresholds(new_thresholds)
If you want to read more about what each argument does, please check out the documentation.
All the passed values and passed_quality_check attributes are dynamically updated when you can .set_quality_thresholds.
# check if the new text now pass the quality filter
doc._.passed_quality_check
False
Comparing Domains#
These quality metrics are heuristic based and need to be tuned. While the defaults are reasonable for some domains, they may not be for others. We will explore this a bit further in this section. These filters are specifically tuned for the web domain and this can lead to problems when applied directly to other domains.
Data#
For this we will use the Danish Gigaword available on Huggingface Datasets. For the purpose of this tutorial we will just use a small test version of it containing around 2500 examples, but you could easily change it to use the whole dataset. Danish Gigaword is a large collection of Danish texts collected from a variety of domains.
We can download the dataset using the following command:
from datasets import load_dataset
# note that this can take a little while
dataset = load_dataset("DDSC/partial-danish-gigaword-small-test-sample")
# All of the dataset is available in the train split
dataset = dataset["train"]
As previously mentioned, the Danish Gigaword corpus consist of multiple domains. For this tutorial, we will look at three of these domains. retsinformationdk which consists of legal documents, hest which contains post from a Danish debate forum (heste-nettet.dk) and spont which contains texts transcribed from spontaneous speech.
# we can filter out these three datasets based on the "source"
legal = dataset.filter(lambda x: x["source"] == "retsinformationdk", num_proc=1)
news = dataset.filter(lambda x: x["source"] == "tv2r", num_proc=1)
speech = dataset.filter(lambda x: x["source"] == "spont", num_proc=1)
We can now examine these datasets a bit more:
print(f"Legal contains {len(legal)} examples")
print(f"News contains {len(news)} examples")
print(f"Speech contains {len(speech)} examples")
Legal contains 1000 examples
News contains 1000 examples
Speech contains 411 examples
We can for example see that the speech dataset contains notably fewer samples than the others.
Quality Filtering#
After we have prepared our datasets we can now start with the quality filtering. Using TextDescriptives, this is extremely simple. We need to do 3 things:
Create a pipeline
Add the quality component to it
Apply the pipeline to the dataset
# 1. Crease a blank spaCy model with a sentencizer as that's the only component required for the quality metrics
nlp = spacy.blank("da")
nlp.add_pipe("sentencizer")
nlp.max_length = (
2000000 # as some of the documents are quite long we can increase the max length
)
# however it might be worth filtering out these documents beforehand for very very long documents.
# 2. Add the textdescriptives pipeline
quality_pipe = nlp.add_pipe("textdescriptives/quality")
# 3. Apply the pipeline to the legal documents
legal_docs = nlp.pipe(legal["text"])
If we check now we can see that legal_docs is a generator. This can be a quite efficient format, but for now we just want to process all the text so we simply need to convert it to a list:
legal_docs
<generator object Language.pipe at 0x1389e1740>
legal_docs = list(legal_docs)
We can now inspect the output here:
legal_doc = legal_docs[0]
print(legal_doc[:100]) # print the first 100 tokens
print("----")
print("This passed the quality filter:")
legal_doc._.passed_quality_check
Den fulde tekst Pressenævnets kendelse i sag nr. 15-70-00822
Resumé
Foreningen for Skånsomt Kystfiskeri har ikke retlig interesse
DR bragte et radioindslag om Natur- og Erhvervsstyrelsens fiskeriinspektorats fangst af ulovlige ålefælder. Foreningen for Skånsomt Kystfiskeri klagede blandt andet med den begrundelse, at betegnelsen ” ålefælder ” er forkert, idet ålene selv kan svømme ind og ud. Pressenævnet afviser at behandle klagen, da foreningen ikke er omtalt i udsendelsen og derfor ikke har retlig interesse.
Pressenævnets formand udtaler:
Det er en betingelse for at klage til Pressenævnet, at
----
This passed the quality filter:
False
Here we see that the text did not pass the quality filter. We can now examine why that using the following code:
legal_doc._.quality
QualityOutput(
passed=False,
n_stop_words=ThresholdsOutput(value=192.0, passed=True, threshold=(2.0, None)),
alpha_ratio=ThresholdsOutput(value=0.8, passed=True, threshold=(0.7, None)),
mean_word_length=ThresholdsOutput(value=4.55, passed=True, threshold=(3.0, 10.0)),
doc_length=ThresholdsOutput(value=500.0, passed=True, threshold=(10.0, 100000.0)),
symbol_to_word_ratio={'#': ThresholdsOutput(value=0.0, passed=True, threshold=(None, 0.1))},
proportion_ellipsis=ThresholdsOutput(value=0.0, passed=True, threshold=(None, 0.3)),
proportion_bullet_points=ThresholdsOutput(value=0.0, passed=True, threshold=(None, 0.8)),
contains={'lorem ipsum': ThresholdsOutput(value=0.0, passed=True, threshold=False)},
duplicate_line_chr_fraction=ThresholdsOutput(value=0.26, passed=False, threshold=(None, 0.2)),
duplicate_paragraph_chr_fraction=ThresholdsOutput(value=0.0, passed=True, threshold=(None, 0.2)),
duplicate_ngram_chr_fraction={'5': ThresholdsOutput(value=0.54, passed=False, threshold=(None, 0.15)), '6': ThresholdsOutput(value=0.52, passed=False, threshold=(None, 0.14)), '7': ThresholdsOutput(value=0.52, passed=False, threshold=(None, 0.13)), '8': ThresholdsOutput(value=0.52, passed=False, threshold=(None, 0.12)), '9': ThresholdsOutput(value=0.52, passed=False, threshold=(None, 0.11)), '10': ThresholdsOutput(value=0.52, passed=False, threshold=(None, 0.1))},
top_ngram_chr_fraction={'2': ThresholdsOutput(value=0.02, passed=True, threshold=(None, 0.2)), '3': ThresholdsOutput(value=0.04, passed=True, threshold=(None, 0.18)), '4': ThresholdsOutput(value=0.07, passed=True, threshold=(None, 0.16))},
oov_ratio=ThresholdsOutput(value=None, passed=None, threshold=(None, None)))
Here we see that fraction of characters which is a part of a duplicate 10 gram is >50%. This is a reason why the sample was filtered out. This is not uncommon for legal documents which contain a lot of standard phrases. However you might wish to change the threshold for this filter. We showed you have to do this in the previous section. We also see that the alpha_ratio is close 0.8. This means that the text is mostly made up of alphabetic characters. This is good, but as we will see later, this is not common for legal texts.
Filtering out the text#
Assuming we don’t want to change the filters we can now use it to filter out the texts that we want to keep:
# 4. Filter out the documents that do not pass the quality
legal_docs_filtered = [doc for doc in legal_docs if doc._.passed_quality_check]
print(
f"We had a total of {len(legal['text'])} which we filtered down to {len(legal_docs_filtered)}."
)
We had a total of 1000 which we filtered down to 264.
That seems like a lot, we should probably check why that is. We can do this by looking at the distribution of the scores of e.g. duplicate 10-gram fraction:
import seaborn as sns
def get_duplicate_10_gram_fraction(doc):
quality = doc._.quality
duplicate_10_gram_fraction = quality.duplicate_ngram_chr_fraction["10"]
return duplicate_10_gram_fraction.value
duplicate_10_gram_fraction = [get_duplicate_10_gram_fraction(doc) for doc in legal_docs]
sns.histplot(duplicate_10_gram_fraction)
<Axes: ylabel='Count'>
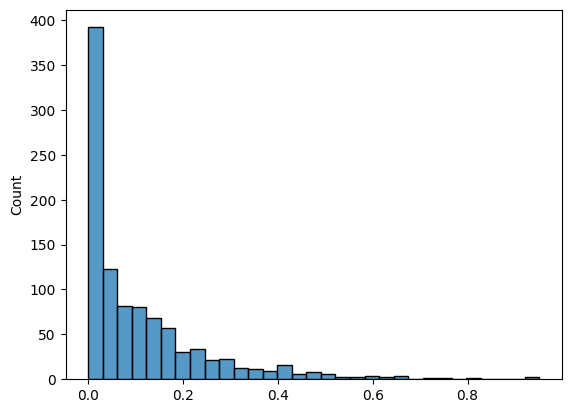
This seems like it explains a lot of the texts which were filtered out, but does not explain everything. Let us take a look at the alpha_ratio (the proportion of words which contains at least one alphabetic character) as well:
alpha_ratio = [doc._.quality.alpha_ratio.value for doc in legal_docs]
sns.histplot(alpha_ratio)
<Axes: ylabel='Count'>
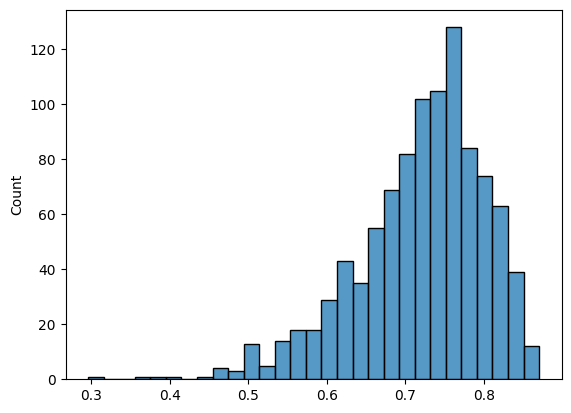
We see that most of the text do not pass the alpha_ratio threshold of 0.7 or higher. This is not uncommon for legal documents as e.g. the paragraph sign § is not an alphabetic character. It might be relevant to change the threshold to 0.7 or lower.
Comparing across domains#
We see that legal documents have quite a few perculiarities let us examine how the alpha_ratio behaves across different domains:
# first we apply the pipeline to the other domains
news_docs = nlp.pipe(news["text"])
news_docs = list(news_docs)
speech_docs = nlp.pipe(speech["text"])
speech_docs = list(speech_docs)
# extract alpha ratio:
news_alpha_ratio = [doc._.quality.alpha_ratio.value for doc in news_docs]
speech_alpha_ratio = [doc._.quality.alpha_ratio.value for doc in speech_docs]
Now that we have the metrics we can plot a histogram comparing the metrics:
import matplotlib.pyplot as plt
# histogram
sns.histplot(news_alpha_ratio, label="News", alpha=0.5, binwidth=0.05)
sns.histplot(alpha_ratio, label="Legal", alpha=0.5, binwidth=0.05)
sns.histplot(speech_alpha_ratio, label="Speech", alpha=0.5, binwidth=0.05)
# add labels
plt.xlabel("Alpha ratio")
plt.ylabel("Count")
plt.legend()
<matplotlib.legend.Legend at 0x144545710>
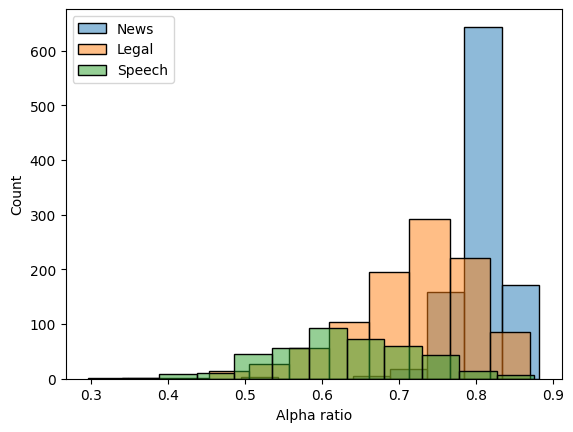
Here we see a couple of things:
A fair amount of legal documents have an alpha ratio above 0.6.
Almost no news text have a alpha ratio below 0.6.
The alpha ratio for the Speech corpus is suspicously low
Let us examine one of the speech samples a bit more in-depth:
doc = speech_docs[0]
# examine the first 100 tokens in the first document
print(doc[:100])
Taler 6: mm
Taler 7: er du klar?
Taler 6: ja
Taler 7: så er spørgsmålet om vi skal- om det er sådan her ja det kunne man godt okay
Taler 7: okay så det er ignore tab kill og kill tab
Taler 6: NA
Taler 6: kill
Taler 6: kill tab
Taler 7: super
Taler 7: okay det er det hun lige har sagt
Taler 6: ja
Taler 6: ja
Taler 6: NA
From this we can see that a high proportion of the tokens in the speech dataset dentoes the speaker such and tokens such as : then lower the alpa ratio. This might or might not be problematic for the task at hand.
Therefore it is important to note that while these filters are useful for filtering large amount of texts it is also important to know that they should be adjusted to the target domain.